This is a post about building an Large Language Model (LLM) -based chatbot assistant for playing the game of Diplomacy. It is the result of work the Jataware / Borgia team has done to date on the DARPA SHADE program, which is focused on building AI tools for complex negotiation and diplomatic situations, using the game of Diplomay as a testbed.
The post is also a demonstration of how to create a chat-based HMI for complex / bespoke / domain specific computational tooling, using an LLM and the ReAct framework. We think this is an underappreciated capability of LLMs with wide applicability.
The idea is:
- LLMs are good at things they learn about in their training, like knowing information on wikipedia, interpreting queries, writing text and code, and simple reasoning.
- LLMs don't know about things that they didn't see in their training, and are bad at "computation".
- When you give LLM’s access to computational tools, a clear natural language prompt that describes how to use them, and some domain-specific information, it massively extends their capabilities, and they are able to glue together the tools in impressive ways.
- LLMs + tools + prompting can be used as generic Human Machine Interfaces (HMIs) for computational tooling. This interface handles a lot of the complexity one *usually* has to consider ex-ante when designing a "frontend" for people to interact with.
1. ReAct
A noted failure mode of zero-shot LLMs is asking a question like "what is the square root of Leonardo DiCaprio’s girlfriend’s age". The LLM (probably) wasn't trained on recent enough webscrapes to know Leo's latest, and LLMs aren't good at computation. But, on some level, this question is *very easy*:
- use google to find out who Leo is dating
- determine her age; and
- use a calcuator to compute sqrt(24)
It turns out that LLMs *can* answer questions like this - questions that require some multi-step reasoning and interaction with things in an environment - if you give them a good prompt and some tools.
The (currently) most popular way to do this is from ReAct: Synergizing Reasoning and Acting in Language Models,
which describes a special case of "chain of thought" prompting. You can also find some examples of
the LLMs + tools + prompting paradigm - albiet, in our opinion, overengineered instantiations of them - in
tools like Langchain.
In general the chain-of-thought / ReAct approach looks like the following:
Our goal with the rest of the paper is to guide you through our problem - making a Diplomacy AI assistant - and how we
used the ReAct framework to solve it.
Design of integrated agents that learn to negotiate effectively atop a strategically robust system remains an open challenge.
Considering these limitations, the idea of "cyborg Diplomacy" emerged. Computers excel at tasks like evaluating possible moves,
assessing the gameplay aspects of treaties, and keeping track of multiple opponents' intentions. However, interpersonal aspects
like convincing another player to form an alliance, making final decisions, detecting deception, and making final decisions about
moves still might be better intermediated by a human player.
Furthermore, one of the most interesting aspects of Diplomacy is the human-to-human negotiation tactics. Could an amateur
Diplomacy player with strong negotiation skills beat an experienced Diplomacy player when armed with a tool to help resolve
some of the strategic aspects?
The goal for our Diplomacy work was to produce a chatbot that could - given some information about the current board state and
access to the tooling we had built - answer arbitrary questions from a player. These questions could range from simple facts the
board state like "who is strong right now" or "what orders should I do on the next turn" that require basic tool invocation, to
complex questions about strategy, deception, agreements, and opponents' intentions, which might require the ReAct LLM to invoke
multiple tools joined together in intricate ways.
The overall schema of the agent is below:
The prompt is a a plain-text or Markdown document that describes to the LLM the overall task, exactly how to respond, and an
explanation of the available tools, data structures, and formatting. It is something between software documentation and a very
specific job description. Prompt 'engineering' is more an art than a science at this stage. Unlike writing code, the effect of
additions, subtractions, and changes of any kind are not obvious.
Powerful LLMs are very flexible. They can correctly interpret misspellings, infer information that isn't clearly stated, and extrapolate very well.
Therefore the upshot is that everything kind of works. On the other hand, its very hard to know how close to optimal the prompt is for a
given task. What's certain is that writing a decent prompt isn't very hard, and writing a very good prompt is probably very hard. Further research
on this, or developing learned / LLM augmented and updated prompts is probably needed.
The introduction is simple, it provides context and the general goal of the agent:
We only actually specify two generic 'tools' the LLM can use directly. The first is clarifying questions, which is self-evident.
The second is the Python **REPL (Read-Eval-Print Loop)** (terminal shell), which is the 'gateway' through which our LLM can interact
with the specialized Diplomacy-specific tooling we have built.
We also specify the 'ReAct' chain-of-thought prompting, and guide the interaction with the software via the formatting.
We finally specify the way the outputs will be returned to the user:
Prior to building our chatbot, we had spent a fair bit of effort building a fully-autonomous full-press Diplomacy agent.
We had already built functions to value board states, select moves, consider counterfactuals, as well as a variety of tools
for proposing, evaluating, as well as defecting from / abiding by treaties between Diplomacy powers. These tools are
primarially built atop diplodocus, a Diplomacy agent trained with human-regularized
RL, which seems to be the state-of-art value/move function. We extend the work by incorporating the ability to value and
decide between treaties of various types, such as peace agreements, alliances, and the like. We pull all of these functions
out of our fully-autonomous agent and expose them with essentially no modification to the ReAct agent.
The last part of the Markdown document consists of providing various examples of questions, the use of tools,
and the expected inputs and outputs. As previously mentioned, its difficult to know how and what to specify here,
but it seems that more and more varied examples improved the performance of the bot.
The LLM is easy, we use GPT-4. Its language and code generation / understanding capabilities are definitely
the best available at the moment, and its ability to do complex reasoning is far better than other available
LLMs. We implement a simple wrapper to keep the chat history and do some simple error handling.
Suppose you're playing as Italy (green in the diagram below). The game is in its 7th year and things are going decently,
you have taken some of central Europe and Africa, and you're trying to understand where you stand, and what you might want to do.
Lets try some simple things like trying to understand the board:
In this section we see the chatbot:
In this section we demonstrate some capaiblities about thinking through a good set of orders:
In this section we see the chatbot:
In this section we try to reason about possible agreements between powers by considering Italy's relatively disandvantageous position:
This section demonstrates the chatbot's ability to:
We hope this specific tool will make the game of Diplomacy more accessible to novice players, and allow them to focus more on
the interesting bit... lying and decieving, coercing and backstabbing. We asked our agent what it would be called to play against
human players using our diplomacy assistant... "Digital Doping", it said. Good luck playing against us at your local tournament.
But beyond the immediate Diplomacy specific use-case, we think our system is a specific example of a powerful general idea: using LLMs
as nocode HMI / chatbot interfaces for complex tooling. Building HMIs is usually a big lift. A GUI, hardcoded functions for
"typical" queries, interpreters for inputing those queries (buttons? dropdowns?), hardcoded workflows, glue code, methods / language /
visualizers to share results, all to make an extremely brittle tool that can only do what the designer thought of ahead of time.
Compare that to our LLM+ReAct+Tooling Diplomacy assistant: it can be queried and respond to in natural language (or code, or a DSL).
In the background (or foreground) it determines and invokes the right "toolkit" calls, glue code, and visualization scripts neccessary
to solve the query. And it returns results in natural language.
Basically, it's a super-fast personal assistant with deep knowledge of a topic area that can implement a tool to solve your domain specific
query, available at scale. This stands somewhat in contrast with the typical useage of LLMs which are totally reliant on
the information stored in the weights of the model (knoweldge, reasoning traces) with the occasional extension of a database store.
We hope this provides a good overview of our diplomacy work - and on the wider idea of LLMs as generic HMIs for
domain-specific tooling. Please leave a comment or reach out with any questions!
zeek, ben @ jataware dot com
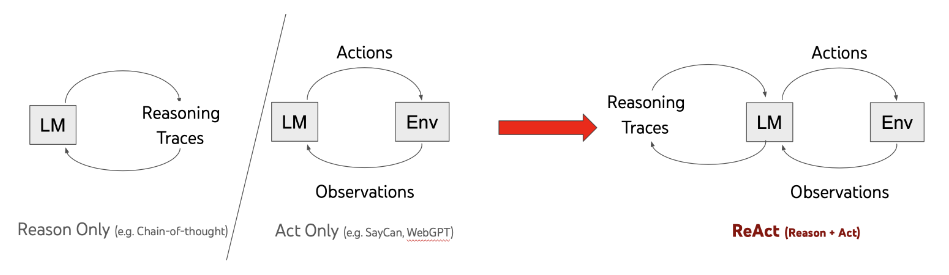
An outline of the ReAct framework vs traditional LLM usage from the original parer
Lost and found in the kitchen
2. Diplomacy + AI
Diplomacy is a strategic board game set in pre-WW1 Europe, where players represent one of seven Great Powers and try to gain
control of the board spaces. The game is simultaneous move, fully deterministic, and zero-sum. However, the rules all but
require players to collaborate, so the interesting aspect of the game is around all the flavors of negotiation: alliance
building, betrayal, deception, coercion, etc... The DARPA SHADE program is interested in Diplomacy
because it provides an excellent surrogate enviroment to study the complexities of real-world negotiation.
Negotiation + Board Strategy = Not Yet
The unique adversarial and collaborative natural-language negotiation structure of the game has made it an interesting
test-bed for AI research. Efforts here have faced several key challenges:
Most recent work on fully-autonomous agents has focused on training agents to play the no-press (no communication) version of Diplomacy.
They have achieved top-human-level performance at the pure "gameplay strategy" aspects of the game through a combination of self-play RL
and human imitation learning. These results show that a very high level of pure board-strategy can be achieved, but don't incorporate any
natural or constrained language communications ... and as such miss the central facet of the game.
... but some progress has been made
Two recent works have taken substantial steps forward on the full-press (full communication) variant of the game: META's
CICERO and Deepmind's Nature publication
Negotiation and honesty in artificial intelligence methods for the board game of Diplomacy.
CICERO showed that a model with an LLM chatgloss can convincingly play full-press Diplomacy and do something like pass the Turing test when playing with other humans.
However, it certainly doesn't display "super-human performance" by many metrics, and is a bit of a frankenstein monster of glued together neural
networks and training techniques - it's purpose built to "solve Diplomacy", but doesn't seem to provide a lot of
lessons for solving tasks like Diplomacy in general. Deepmind's paper shows that things people negotiate about -
a treaty or agreement, breaking an agreement, getting revenge - can be thought about in terms of computable quantities,
and algorithms can be used to effectively value and choose between various fuzzy concepts.
Render unto caesar...
3. Building a Diplomacy ReAct Agent
A task-specific chatbot consists of 3 things:

schema of our diplomacy / react chatbot
The Prompt
Introduction, core tools, and formatting
You are a bot that assists people playing the board game Diplomacy.
Your job is to answer the user's questions as best you can.
You respond only in json that can be parsed by Python's json.loads function.
You have access to the following tools, which can help you in your task:
- `PythonREPL`
- This tool is a python shell. Use it to execute python commands.
- If you expect output, it MUST be printed to stdout with the `print` function.
- You should use multi-line formatting to avoid syntax errors.
- Note that you have access to anything you've computed in previous calls to `PythonREPL`.
- _Input_: a valid python program.
- _Output_: sys.stdout for the program.
- `ClarifyingQuestions`
- This is a tool that you can use to ask the user clarifying questions.
- You can use this tool if you don't think you have enough information to answer the question.
- You can also use this tool if you think you're stuck and you want the user to help un-stick you.
- _Input_: question (in English)
- _Output_: answer to the question (in English)
Every response you generate should be in the following JSON format:
```
{
"thought" : # you should always think about what you need to do
"tool" : # the name of the tool. This must be one of: [PythonREPL]
"tool_input" : # the input to the tool
}
```
## Tool Evaluation + Iteration
After you respond in the above format, we will run `tool(tool_input)` and return the output to you in the following format:
```
{ "observation" : # the output of tool(tool_input) }
```
You can then use the formulate another `{"thought" : ..., "tool" : ..., "tool_input" : ...}` as needed, until you're convinced you have the answer to the question.
## Final Answer
When you are confident you have the correct answer, output the answer in the following format:
```
{ "answer" : # the answer to the question }
```
The Diplomacy specific tooling / python functions
In the `PythonREPL` tool, you have access to the following functions:
- `get_state`:
- Returns the current board state of the diplomacy game.
- _Inputs_: null
- _Outputs_: dictionary, representing board state.
- `get_values`:
- Returns the expected value of the current board state for all of the powers.
- Higher expected value is better.
- _Inputs_: (Optional) dictionary, where keys are power names and values are lists of treaties for that power
- _Outputs_: dictionary, where keys are power names and values are probability of winning the game
- _Notes_:
- Call this function multiple times to compare the expected value subject to treaties with "unconditional" values (no treaties). Treaties that increase the expected values for a given power are good for that power, but treaties that decrease the expected value are bad and should be avoided!
- `get_possible_orders`:
- Returns all possible orders for each location on the board.
- _Inputs_: (Optional) dictionary, where keys are power names and values are lists of treaties for that power
- _Outputs_: dictionary, where keys are map locations and values list of possible orders for that location, in `ParsedOrder` format.
- `get_likely_orders`:
- Returns good / likely order sets for each power, based on a neural network policy function.
- _Inputs_: (Optional) dictionary, where keys are power names and values are lists of treaties for that power
- _Outputs_: A dictionary, where keys are powers and values are lists of likely order sets for that power, in `ParsedOrder` format.
- `get_br`:
- Returns "best response" order set for a given power, based on a neural network policy function.
- _Inputs_:
- power: Name of power to compute best order set for
- treaties: (Optional) dictionary, where keys are power names and values are lists of treaties for that power
- _Outputs_: A list of orders, in `ParsedOrder` format.
- `get_joint_orders`:
- Returns mutually beneficial orders for a pair of powers, based on a neural network policy function.
- _Inputs_: The names of two powers
- _Outputs_: A dictionary, where the keys are the power names and the values are lists of orders, in `ParsedOrder` format.
Examples
- User: "Question: What are the possible orders for the army in Moscow?"
- You:
```
{
"thought" : "I need to get all of the possible orders for the army in Moscow.",
"tool" : "PythonREPL",
"tool_input" : "
poss = get_possible_orders()
print(poss['MOS'])
"
}
```
- User:
```
{ "observation" : "[{'datc': 'A MOS S A STP - LVN', 'type': 'support', 'node': 'MOS', 'source': 'STP', 'target': 'LVN', 'node_unit_type': 'A', 'source_unit_type': 'A', 'node_power': 'GERMANY', 'source_power': 'GERMANY', 'target_power': None}, {'datc': 'A MOS S A UKR', 'type': 'support_hold', 'node': 'MOS', 'source': 'UKR', 'target': 'UKR', 'node_unit_type': 'A', 'source_unit_type': 'A', 'node_power': 'GERMANY', 'source_power': 'TURKEY', 'target_power': 'TURKEY'}]"}
```
- You:
```
{ "answer" : "
The possible orders for the army in Moscow are
- supporting A STP - LVN
- supporting A UKR
"}
```
LLM
import openai
class ChatGPT:
def __init__(self, model='gpt-4', system=""):
self.model = model
self.system = system
self.system_message = {"role": "system", "content": system}
self.messages = []
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
if 'ERROR: You sent the following' in message:
# Drop error + correction from chat history
self.messages = self.messages[:-3] + self.messages[-1:]
return result
@retry_decorator
def execute(self):
completion = openai.ChatCompletion.create(
model=self.model,
messages=[self.system_message] + self.messages,
temperature=0,
)
def pprint(self):
rprint(self.messages)
4. The system in action
Board State
Orders
Treaties
5. The upshot
Using the assistant isn't restricted to someone who has a good knowledge of Diplomacy, game theory, computers,
or the computational tooling we have developed. Anyone who can read and write can use it. And they can use it in ways we havent' already concieved of;
the diplomacy assistant can glue together complex tooling, interpret unforseen results, discover where it fails, and know what it doesn't know.